

Whether you are a developer who is new to SQL and wants to learn the basics or an experienced developer who wants to pick up some new ideas to help tune the performance of your queries, this article will lay out the foundation for the analysis of a query and how to get the most out of your analysis efforts. Many performance issues could be solved just by going through a simple checklist. For example, is Explain Plan on your radar? If not, it should be. It’s time to optimize your SQL query and cut out those practices that are costing you time and mistakes.
Types of Problems
It’s 8am on a Friday and you’ve just checked your inbox. The CMO has asked you to produce a Sales Dashboard for their last-minute meeting to create a report from various tables in the database.
The dashboard you’re supposed to create needs to show a summary of metrics across numerous different business areas, however. This means you now have to pull together a lot of data. Not only that, but you’re having to filter and aggregate it to show the executives the bottom line. They don’t want to see raw data: they want to see only a snapshot. Now you’re tasked with putting together a number of SQL queries that are more complex than normal. Dashboards involve complex queries, pulling together a lot of information, and stitching it all together into a view that’s easily digestible by the CFO, CMO, and CEO. So, how do you save yourself time and extra work while still delivering a dashboard that performs well and doesn’t cause excessive load on the database?
Creating indexes takes time and can adversely impact database performance. In addition, if indexes are not properly created, a SQL Server must go through more records to retrieve the data requested by a query. This results in longer waiting periods and the usage of more hardware resources. While you may think that your indexes are running efficiently, you would be amazed at the increased performance and decreased database load that can result by developing a comprehensive indexing strategy.
Source: Stitched together Dashboard example
We will first discuss how to improve query performance by walking you through the effective use of indexes, followed by joining strategies, then discussing query structures, and finally introducing you to the Explain Plan. The combination of these principles will help guide you through creating an efficient and effective system to optimize your SQL queries.
Effective Use of Indexes
Indexes can be compared to a card catalog in a library. In a library, the books are organized by subject/genre and are on the shelf in a physical order. Additionally, you are able to look in the card catalog and know exactly how to get to the one specific book you need. Unnecessary time spent searching and wading through other books is cut out. This is the idea of the range scan. By being able to go straight to the subject or genre you are wanting to read, you no longer have to go through and look at every single book in the library to find the ones you are interested in.
The proper use of indexes is to create one that will basically restrict the number of “books” you need to look at before finding the one you actually want. Narrowing down the search with your index will help you only scan through a small range of records.
While indexes help, there is a cost. Every index must be updated each time data is inserted into the table, which takes time. Many developers create too many indexes. It is critical to look at your application holistically and locate your bread and butter queries – the ones that are expensive and that run frequently. These are the essential queries that must be working properly and that need to have effective indexes created that will allow the query to work fast. When you consolidate indexes and eliminate those that are redundant, you are allowing your key queries to perform at their best.
Example:
This is a simple example that illustrates the concepts of index usage. You have a party table that contains the list of suppliers and customers and a party_address table that lists the addresses for each party.
Let’s suppose that you regularly need to retrieve a list of customer addresses by a range of postal codes.
We currently have 3 indexes on the table: the primary key index, an index on the party id (party_addresses column) & address type, and one on the address fields: Address 1 &2, City, State, & Postal Code.
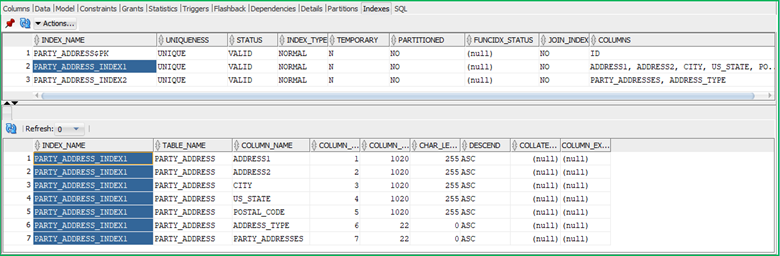
Even though the index contains the postal code, the SQL complier doesn’t use it because it is the 5th column on the index. The columns that are used to filter the data need to be at the beginning of the index field list.
A simple query that joins the party and party_address tables and filters by a range of zip codes is not able to use the index, thus forced to perform a full scan of the table to find the records.
SELECT party.name, address1, address2, city, postal_code, us_state
FROM party
JOIN party_address addr ON addr.party_addresses = party.id
WHERE addr.postal_code BETWEEN ‘75000’ AND ‘75999’
AND addr.address_type = 0
Adding an index, or better yet, modifying the existing index to place postal code as the first column, reduces the cost of the query by 90%.
Composite Indices & Function Based Indexes
A composite index uses multiple values (columns or functions) to group and order the rows in the table. The index will use the first column to order the data and then use each of the remaining columns to break ties.
For example, let’s say you have a customer table and want to be able to search the data by the customer name. You can create a composite index on:
- Last Name
- First Name
- City
- State
The index will organize the rows by Last Name, with all the Smith’s together and ordered by first name. Customers with the same First Name and Last Name will be ordered by City and State.
Indexing improves the performance of filtering and sorting operations. With a composite index, the ordering of columns is crucial. For maximum efficiency, it is important to set up the index in a way that the leading columns are used to filter the data and the trailing columns to order the data.
To target promotions for customers in both specific states and cities, the index created above would not be effective. Rather, reordering the index or creating a new index on the following would be more effective:
- State
- City
- Last Name
- First Name
This index would allow customers in Georgia or in Chicago, Illinois to be quickly found using a Range Scan.
In most cases, a composite index can replace a single column or composite index that contains the leading columns of the new columns in the same order. An index on State, City, Last Name, and First Name can eliminate the need for an index on State and an index on State and City. It will not eliminate the need for an index on Last Name, however, because Last Name is not a leading column.
A functional index uses the value of a function to organize the data. Functional and composite indexes are not mutually exclusive. A function can be used whenever a regular column can be used in an index.
A common example is a case insensitive search. Creating an index on LOWER(description) would allow a case insensitive search on the description column. For the index to be used to increase the performance of a query, the query must use the same function on the column as is defined in the index.
WHERE :searchTerm = LOWER(description)
(this assumes that :searchTerm is already lower case)
If you are not sure if a query is using the function index, check Explain Plan.
Joining Strategies
Inner and Outer Joins
When working with inner and outer joins, the best practice is to avoid outer joins when possible. Outer joins, most commonly, are more expensive than inner joins.
A potential strategy to eliminate outer joins is to make joining field(s) not nullable and create a default value (id=0) for an unknown value. This allows the query to use inner joins without dropping records. This is only possible when you are designing the data model and typically isn’t feasible.
An inner join focuses on the commonality between two tables. When using an inner join, there must be at least a match between the tables that are being joined (e.g. customers without an address would be excluded).
Deferral of Joins
Rather than creating a join and filtering afterward, your system will run more efficiently when you first filter and then create your join. Anything you can do to narrow your data early in the execution of the query will end up saving you time and resources in the long run.
d=0) for an unknown value. This allows the query to use inner joins without dropping records. This is only possible when you are designing the data model and typically isn’t feasible.
An outer join returns a set of records (or rows) that include what an inner join would return, but also includes other rows for which no corresponding match is found in the table being joined to (e.g. customers without an address record are included).
Elimination of Joins
Finally, the restructure of your query to allow for the elimination of some joins entirely could benefit you greatly. By eliminating those joins that are not essential, you are eliminating work that you should not have to be doing. For example, by changing a query to use a product id rather than a part number, you could eliminate the need to join to the product table to look up the part number.
Query Structure
Narrowing the playing field as soon as possible in the execution plan will yield get results. You can do this by taking advantage of range scans and avoiding full table scans of large tables when possible. When your data has been organized and narrowed down correctly, you are then able to create indexes that will allow your key queries to work at a fast rate. Because the SQL compiler will try to rearrange a query for maximum performance, it is important to not make its job harder and always structure your queries for efficiency.
Using the Explain Plan
Have you ever been thrown into a broken process and asked to fix it? Maybe your manager has complained that the Dashboard on the Home Page is taking 2 minutes every time to reload the nine queries, however you’ve been told that you don’t need to look at the queries because they’ve been extensively analyzed by experts?
Once you’ve convinced them to let you investigate, you can run explain plan to assist your analysis and identify the best avenues to optimize your query.
With Explain Plan, you might able find that the source of the delay is that it is going through every record in a 5 million record table when it only needs to go through 10.
In this example, the mistake was not using an index to allow it to look at only those 10 records. Rather than utilizing a range scan, they were running a full table scan. The Explain Plan identified the issue and the changes to the query made it almost 10,000 times faster.
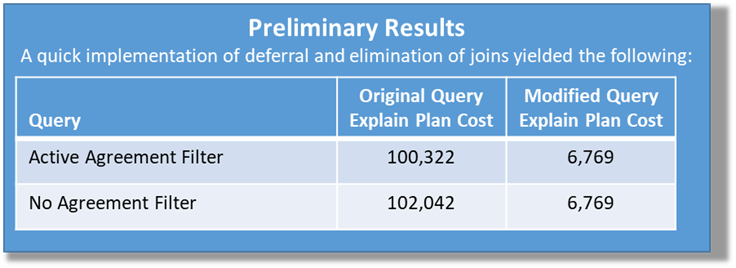
In my over 20 years of experience working with clients in numerous different industries and assisting with SQL Optimization, I have been surprised by how many developers do not know about the Explain Plan.
Cardinality is the estimated number of rows that the step will return.
It may seem basic, however, if you are not using it, it could cost you. The Explain Plan shows the SQL compiler’s strategy for executing your query and is based solely on database statistics. It also shows both cost and cardinality.
Cost is the estimated amount of work the plan will require.
When looking at the plan, finding those steps that are driving your cost is essential. Because a query with a higher cost will use more resources and thus take longer to run, the cost is your prime driver. It is important to remember, however, that although full scans are warning flags and may seem like a step to always revise, they sometimes are needed. Overall, using the Explain Plan will not only help things run much faster but will also help you discover which steps are necessary and which steps need to be revised.
Simple Explain Plan Example
This is an extremely simple example of an explain plan that shows the Addresses by Zip Code query from earlier before and after the index optimization. This is not a tutorial on Explain Plan, but hopefully will inspire you to learn more about the tools offered by your database.
The plan shows that because the postal code field did not have a usable index, the query required a full scan of the entire table. This step accounted for almost all of the cost (213 of 225).
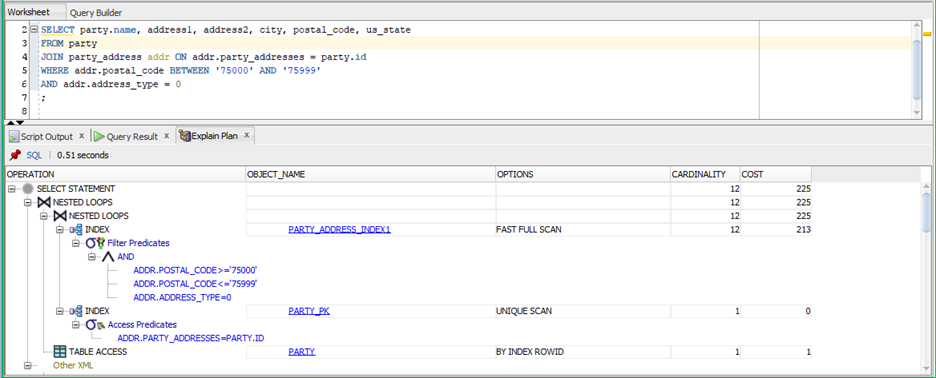
After the index was modified to have the postal code as the first column, the query was rerun and Explain Plan regenerated:
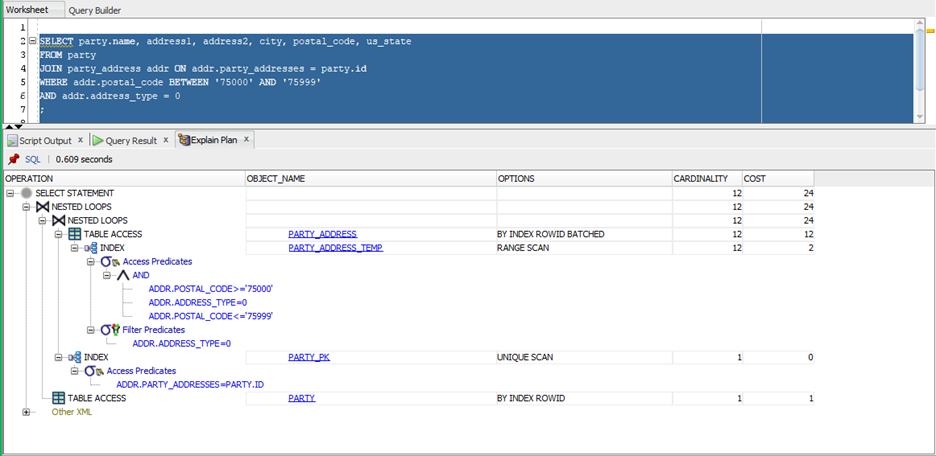
Notice that now the query is able to use the index (Party_Address_Temp) and perform a Range scan of only addresses with a Postal Code between 75000 and 75999. This reduced the cost of this step from 213 to 14 (12+2) and the total cost was reduced by 90%.
Obviously, this is not a query to spend much time optimizing, but it illustrates the concepts. When you have queries with costs of 10,000 – 1,000,000 and numerous complex joins, the time spent in analysis can make a significant impact on your application’s performance.
The Results
No one would say no to a faster and more responsive database. Many of your performance issues could be solved just by going through these sections and applying the principles.
While it may seem simple and appear to be just the basics, knowing and applying these principles can completely transform your system and lay a solid foundation for both the present and future.
If you’re experiencing any performance issues, we’re happy to help.